
If you are reading this and about to interview with me, bravo! Yes I will ask you some of these, and I've been asked others. These are all real-world questions that you should be familiar with when writing embedded code, embedded defined as bare metal with maybe a little FreeRTOS written in C. Ace these questions in a phone interview and you might just get invited down to the ranch.
What coding environment do you have Setup on you System?
Ok, I have not asked this. Just thought of it recently, but I have coding tools on my personal computer, which might just come in handy if asked to perform a breadth-first tree search or fizzbuzz. No need to bang out code on some unfamiliar online editor or, heavens forbid, shared Word document. Just act casual and go "Ok, let me just share my screen..." and start working. When they say "Oh it doesn't need to compile..." you say "Oh no, you asked this on a phone interview; we're doing this until it compiles and runs and I might even make a few unit tests." A textbook example of coding disobedience.
For compiling C/C++ you can download Microsoft Visual Studio. It just works, although you get no nerd points. To earn nerd points, setup VS Code on your Windows machine with MSYS2/mingw so you can regale them with tales of subtle shell profile failures. To get the most nerd points, setup WSL with Neovim and a full set of custom keyboard shortcuts for your Kinesis split keyboard. Bonus points for specific embedded IDEs like Segger, Rowley Crossworks or silicon vender IDE. Of course, if you go this far, why not get a dev board from some nice MCU vender and start a project that you can show off in your interview.
Why would you use the keyword volatile in an embedded system?
Now this is something you should definitely know, forget to use, get burned by, swear "never again" only to eventually relive past failures. MCUs have RAM, registers and sometimes cache. The compiler enjoys optimizing and may decide to copy an oft-used variable to a register to speed things up (as register access is faster than RAM). Now say you read a variable in main-line code and the same variable is written in an interrupt service routine. If the main-line code loaded that variable into a register for faster access, but then the ISR sneaks in and updates the value in RAM, the main-line code will have (and use) the stale value in that register. Another example, being this is embedded code, "registers" may very well refer to a hardware interface register containing, for instance, a nice fresh ADC reading. The compiler may take that value and stick it into a general purpose register for later use, then the ADC hardware interrupt comes in and loads an even fresher value. But the code will use that stale value instead. The solution? Put "volatile" in front of the declaration of a variable to tell the compiler never to optimize reading/writing of said variable. Always read/write to the memory location and never cache/otherwise optimize it. Use volatile whenever a variable is accessed by main-line code and an interrupt, or by two different RTOS tasks. Additionally, poke around enough in smart people code and you'll see "__asm volatile (some assembly instructions)" like this example from FreeRTOS.
void vPortStartFirstTask( void )
{
/* The MSP stack is not reset as, unlike on M3/4 parts, there is no vector
* table offset register that can be used to locate the initial stack value.
* Not all M0 parts have the application vector table at address 0. */
__asm volatile (
" .syntax unified \n"
" ldr r2, pxCurrentTCBConst2 \n"/* Obtain location of pxCurrentTCB. */
" ldr r3, [r2] \n"
" ldr r0, [r3] \n"/* The first item in pxCurrentTCB is the task top of stack. */
" adds r0, #32 \n"/* Discard everything up to r0. */
" msr psp, r0 \n"/* This is now the new top of stack to use in the task. */
" movs r0, #2 \n"/* Switch to the psp stack. */
" msr CONTROL, r0 \n"
" isb \n"
" pop {r0-r5} \n"/* Pop the registers that are saved automatically. */
" mov lr, r5 \n"/* lr is now in r5. */
" pop {r3} \n"/* Return address is now in r3. */
" pop {r2} \n"/* Pop and discard XPSR. */
" cpsie i \n"/* The first task has its context and interrupts can be enabled. */
" bx r3 \n"/* Finally, jump to the user defined task code. */
" \n"
" .align 4 \n"
"pxCurrentTCBConst2: .word pxCurrentTCB "
);
}
Imagine the disaster if the optimizer said "Well vPortStartFirstTask() isn't doing anything because there's no C code inside so I reckon
I'll just delete the whole thing." Equally bad, since pxCurrentTCB is in fact a global C variable, the assembly may not be deleted,
but the block might be moved!?. What are you doing optimizer? No! This volatile business is extra annoying as it usually rears it's
head in the release build where the optimizer is on, but the code works fine in debug mode where the optimizer is typically off. So if
your code works fine until making the release build, go back in and look for missing volatile keywords. It's not the only reason release
builds fail, but certainly one of them.
Here's a link with more info on the subject:
Tech Explorations
What's static vs dynamic memory allocation?
An important distinction in C programming with extra special interest in embedded programs expected to be robust. Static memory allocation is defined
at compile time. For example, if you put this at the top of your file:
static uint8_t uartRxQueue[256];
That array is defined at compile time and the compiler allocates 256 bytes of RAM and that RAM is associated with uartRxQueue[] for the duration.
Alternately, you could dynamically allocate the array at runtime only when the UART connection is active.
uint8_t *pRxQueue;
if(uartIsActive)
{
pRxQueue = malloc(256);
}
else
{
free(pRxQueue);
}
In C, dynamic memory allocation is synonymous with malloc() and free(). Why use it? If the system has decent memory (tens of KB), but not enough to statically allocate all required buffers, for instance, and all the buffers are not needed simultaneously. Now you may have heard tell that using malloc in an embedded system is a no no. I heard that and never use it. But why? The first argument against malloc is C has no garbage collection so you have to make sure to call free() when you want that memory back. This can be easier said than done and whenever the podcasts bring up RUST they inevitably meander to C's unsafe memory with a side of malloc(). There is also overhead and fragmentation, a general concern that becomes larger with more complicated mallocing. First, there's the actual library code imported to use malloc/free which eats up some flash, then there's the RAM used to store allocation metadata. For instance, if you were wondering how free(pRxQueue) knows how much RAM to free, it's because malloc() saved metadata containing pointer and memory size information. If you have a bunch of dynamic memory malloced at the same time, you can also get fragmentation (another thing garbage collectors usually take care of). Imagine the program malloc/frees a bunch of buffers in addition to pRxQueue(), some larger, some smaller; and numerous mallocs active simultaneously. You can get into a situation where some memory is free'd but too small for use in the next malloc, and remains unusable for who knows how long. You can end up in a similar out of memory situation to forgetting to call free(). That's why static memory allocation is your friend. Old, reliable static memory allocation. All you need to worry about is buffer overruns and errant pointers stomping on strings causing mysterious question marks on the display.
How about data vs stack vs heap? Where's stuff going anyway?
Stuff being variables, data and such. They go somewhere, like this:
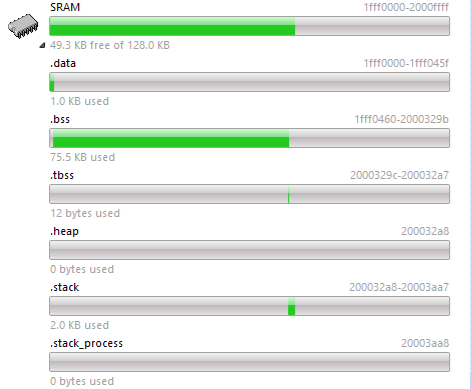
So what's .data, .bss, etc?
- .data - This is the initialized data segment, where global and static variables initialized at compile time go. The compiler puts them in flash, then startup assembly code loads them into the .data SRAM segment. This is the segment to keep big initialized setup structures out of (foreshadowing!) or they'll hog up RAM.
- .bss - This section holds uninitialized global and static variables.
- .tbss - Thread Local Storage bss; FreeRTOS would use this to store uninitialized variables unique to each thread.
- .heap - Where dynamically allocated memory resides. In the example image there is none because this program does not use dynamic allocation.
- .stack - The stack manages function calls and is where non-static variables defined inside functions (local variables) go.
Some further thought on the stack; in embedded systems, you need to define it manually because there's no magic. PCs use magic; virtual memory and dynamic allocation to grow the stack if needed. They also allocate a large amount (for a stack) by default. You can see how much with a PC tool like VMMap; my laptop is currently allocating 7 MB, for instance. But on an embedded system, you can easily blow the stack. What is that? Using more than you allocate, potentially stomping on some other used RAM, causing problems. That's why it's common to manually insert a stack check. Put a known value (0xDEADBEEF being popular) in the bytes at the end of the stack and check them periodically in the main loop or timer interrupt. If overwritten, the stack is blown! When debugging you can set a breakpoint for this condition. For release, just reset or save a flag to non-init memory...what's non-init memory?
Why avoid recursion in an embedded system?
Gee I wonder why this section is right after all that talk about blowing the stack? Recursive functions call themselves over and over. Function arguments, local variables, return address and frame pointers go on the stack. More stack is used with each call. Do it enough and boom, blown stack. That's why you generally want to avoid recursion. On a PC, you have way more stack memory, and the OS will dynamically allocate more, so recursion within reason is generally fine.
What do the static and const keywords do?
The static storage class specifier; let's get the short definition direct from the K&R C Programming Language book...wait. The cover looks like that one but it's written by some other guys. I've had this book forever and always thought it was the K&R book. So I have the programming book equivalent of a "Sounds Alike". Honestly I feel a little betrayed. So direct from "C, A Reference Manual"...pff, the static keyword stops the function or variable from being exposed to the linker. That means you can't get at the variable or function from another C file by using the extern keyword. Why use it? The static keyword is an important part of encapsulation, separation of concerns and general modular programming. It enforces those concepts; acting the part of a KEEP OUT sign, encouraging the use of interface functions. Thinking modular is a SOLID way to go (ha Ha!) as it helps deter the dreaded spaghetti code where everything is closely coupled, fragile, insipid. Bland, un-salted steak cut fries in a dixie cup. You eat them only because they are there. You can try this immediately in your newly installed MS Visual Studio or 5 hours later in VS code setup to run mingw. Just make these two files.
StorageClass.c
int myLocalVariable = 0;
int GetLocalVariable(void)
{
myLocalVariable++;
return myLocalVariable;
}
main.c
#include
This will compile and run just fine until you put static in front of the declaration for myLocalVariable or GetLocalVariable(). Do That and the build will fail with an "unresolved external symbol" error.
But! There's always a but. What if you're working on a PIC16F13145. This thing has 14 KB of flash and 1 KB of RAM. Pretty small. Not to brag, but back in the day I used one that had like 2KB ROM and 128 Bytes of RAM...think that just means I'm old. There's no way you're going total static on one of these. The tiny PICs I used had dedicated 7-level deep stacks that only stored the return address, and getting to main used I think two slots. In these systems you have limitations that result in the need for reusing Bank B RAM; externs come with the territory.
And! There's sometimes an and. What else does static do compared to say, auto? The auto storage class specifier is the default; it just means local scope. But local scope is important within a function. Local scope in a function means it goes on the stack and is deallocated when the function returns. But what if you want to keep some state in the function? (Haskell developers just clicked away). Put static in front of the variable declaration and it's off the stack and into the data segment. Now you have persistent state in your function without declaring the variable at the file level (also using static), which is nice for data encapsulation. If you declare the variable where it is used, it makes the code clearer; in the function if only used there, in the file if used by several functions in the file, global if writing code on a tiny PIC and you have to.
Now for const. Declaring a variable or pointer as const means various flavors of "you can't change it". Yunus did a great job explaining const in this post. I use const a bunch for configuration data, which often comes in the form of a const struct. I made a menu system, for example, that is table-based. The tables are just arrays of structs. Lots of structs. These are all initialized when declared, and without const, they'd all go into RAM, needlessly hogging up a bunch of RAM for no reason, if not causing an out of RAM compiler error. The compiler will put data declared const into flash. Menu table problem solved.
You can also use cost to enforce type safety. For instance, say you have a constant value of 2500 that you need to pass around or use in an equation. You could make a define for that. But a define does not inherently impart a data type; it just substitutes text. If you set your warning level to /Wall, you may just get some data type warnings when the define is used. Set your compiler to treat warnings as errors and you'll have to deal with these warnings, adding an explicit typecast where used, or to the define. Making an actual const variable imparts the intended type at declaration. Unfortunately, it also makes you use externs in the header file with declarations in the c file, which is gross. Kinda liking defines and /Wall right now. /Wall; your frustrating, annoying pedantic coder friend.
What does the keyword inline do? Why would you use it? What gross thing does it replace?
Easy one! Unless you forgot about it. When inline is applied to a function declaration, it tells the compiler to insert the function's code in place of the function call, thus avoiding the overhead of actually calling a function. So you're trading compiled size for more speed. Gotta small function that get's called repeatedly in a processing loop? Perfect place for inline. Inline also tells the compiler to ignore multiple definition errors for the function, so you can put the function definition into a header file if desired. What does it replace? Ugly garbage multi-line macros that are horrible anathema don't use them. But! There's always a but. The compiler takes inline as a suggestion. A pretty please, if you will. So it might not actually inline the code. That's where the ugly macro comes back in. Since a macro is just direct text insertion, the compiler will direct text insert, period.
What type of buffer might you use to temporarily store bytes coming in from a UART for parsing later?
Super fun question that a bunch of people that I asked did not know. Dare I say most? Don't let that be you! A FIFO. Stands for "First in First Out". Oft implemented as a circular buffer. Foreshadowing a future "Whiteboard Problems I May Ask"? Why use a FIFO for this? Because UART receive logic is oft tied to the UART receive interrupt. The parsing is normally done in the main line code at some time when the program is not busy doing something else. AND we don't want to loose bytes now do we? The UART receive hardware for the MCU might have a hardware FIFO, but typically it can only hold a scant few bytes. So to ensure the received bytes are not lost while the code is off doing other things, it's generally a good idea to, in the UART receive ISR, throw the received bytes into a software FIFO capable of holding a bunch of bytes.
How can you conserve RAM when passing a large structure into a function?
This comes again from real life. Short story. Once upon a time somebody used up gobs and flobs of stack and blew the stack by passing large structures by value into multiple nested function calls. Luckily, there's an easy way around that. Pass the structure by reference, AKA pointer. Sure that's not always desirable because code in the function could change a value in the original structure and you might not want that. So use the previously mentioned const keyword on that pointer. Now, somebody tries to sneak an assignment in they'll get an error, erase the const and then do it anyway.
How might you implement a state machine in C?
First, if needed, go forth and learn what a state machine is. I was surprised how many applicants were unfamiliar with the concept. The answer will then be obvious as most trivial state machine examples are implemented using a switch statement. But go deeper and try implementing more complicated hierarchical state machines. You can do this with switch statements or other ways - I even wrote a blog about it. Most non-trivial embedded systems will benefit from hierarchical state machines as you can organize functionality/features into separate files for easier understanding and maintainability.
When would you use an RTOS vs bare metal?
Get'n a little into system design. I was once given the brushoff from an HR person at one of those employer jamborees where you walk around wearing old suit's and hats going "meh...see? What-ya gonna do now see?" and other such '30s gab. Anyway, this individual said once you have, like VxWorks or something, experience, your possibilities just open up. And I agree, they open up at that one company. But I've written a bunch of embedded code for pump systems, large tonnage chillers, large airplanes and small handheld meters, and I needed an RTOS one time. And that was...drum roll...when integrating a library that took bunch-o-cycles to calculate stuff and the system still needed to remain zippy with button presses and screen updates. So put the library execution into a low-priority task with button/screen services in higher priority tasks. I say tasks because once I had the RTOS I made up some other reasons to have like 4 tasks why not?
Generically, the reason to use an RTOS is if you have bunch of "code A" and other bunch of "code B". Code A needs to run toot sweet, like in response to an interrupt, and code B not so much. So code B's live'n life and boom, interrupt; the ISR sets the RTOS event to run code A. If setup as priority-based, with code A higher than code B, the RTOS then stops code B and runs code A. Why not just put all of code A into the interrupt? That be kinda like an RTOS, and for simple systems, by all means do that. But as systems get bigger you generally don't want to start jamming lots of code into interrupts. "Creative Use of Prioritized Interrupts" is not a Udemy course. Also, there's mutexes, semaphores, message queues and events that come in handy when using multiple tasks, things that creative interrupt usage does not support natively.
What are the two main ways an RTOS can be used to control task execution?
Priority and Round-Robin. Almost nobody knew this. Like I think one person knew this. So your welcome. Priority-based, as alluded to above, is where you setup several RTOS tasks and give each one a priority. Higher priority tasks preempt lower priority tasks. In Round-Robin, you setup multiple tasks of equal priority and a fixed amount of time (time slice or quantum) that each task can run before blocking (stopping) to let other tasks run. For example, you could setup 3 tasks and a time slice of 100ms. When started, task 1 would be allowed to run for 100ms, then stopped and task 2 started. Task 2 gets 100ms, then onto task 3. The cycle then restarts with task 1.
What is the difference between a mutex and a semaphore?
Why am I asking so many RTOS questions when I only used it once? Maybe it truly does open up a world of opportunity. A mutex locks a shared resource, ensuring exclusive access to it. For instance, if you have a data structure that is updated in one task and an interface function lets other tasks grab it for their own evil purposes, you don't want those other tasks grabbing a partially updated data structure now do you. So use a mutex to lock it. The update task locks the mutex, updates the structure, then unlocks. If in the middle of that some other task preempts and tries to get the partially updated structure, it blocks on the mutex until the first task completes the update/unlocks it. I've used mutexes.
I've not used semaphores. Not saying they're useless. Just have no need and feel they're useless until I have a need then I'll think they're great. Semaphores are counters that you can apply to the use of a limited resource. Think of this as an example; you're not to use malloc as previously stated, so instead statically allocated an array of 10 structures (oft called slots by me). Various tasks periodically need to use a slot but there's only so many, so you put a semaphore on it. When a tasks wants a slot, it takes a semaphore, incrementing the number. When done it gives it back, decrementing the semaphore. If all the slots are spoken for and a task tries to take the semaphore, the world explodes or something. Again, I don't use them. You can also use semaphores for synchronizing between tasks. I read about that once and said "Boring!". But I'll remember if I ever need to do that.
Ok, I have too many questions.
This blog will become my next novel if I continue. So I've decided to do a series. What will they be about? Well you're just gonna have to check back in to find out.